【7k长文,一次到位】前端八股文再来一遍🧐(图解 + 总结)
所谓打好地基再盖楼,此文就从前端八股文开始,一起踏出前端职场人技术成长第一步!!!
正文
作用域和闭包
什么是作用域链?
当访问一个变量时,解释器会首先在当前作用域中查找标识符,如果没找到,就去父作用域,直到找到该变量的标识符或没找到。这条寻找的链路就叫作用域链
什么是闭包?
在JavaScript中,根据词法作用域的规则,内部函数总是可以访问其外部函数当中声明的变量;当调用通过外部函数返回的内部函数时,即使此时外部函数已经执行结束,但是内部函数所引用外部函数的变量依然保存在内存中,我们把这些变量的集合称为闭包
闭包是怎么产生的?
当函数存在对其所在词法作用域的引用,而该函数被拿到当前词法作用域外执行,此时就产生了闭包。
(使用场景)在工作中,哪些地方使用到了闭包?
- return一个函数,函数内存在对上级作用域的引用
- 函数作为参数(对于下面这个场景,看闭包的上级作用域是什么就知道了)
```javascript
var a = '林一一'
function foo(){
var a = 'foo'
function fo(){
} return fo }console.log(a)
function f(p){ var a = 'f' p() } f(foo()) // ‘foo’
- IIFE自执行函数
- 其实在定时器、事件监听器、Ajax请求、跨窗口通信、Web Workers 和 任何其他的异步(或同步)任务中,只要使用了回调函数,实际上就是在使用闭包
### 能不能实现一个闭包?
- 1
```javascript
function foo(){
var a = 2;
function bar(){
console.log(a);
}
return bar;
}
var baz = foo();
baz(); //2 —— 这就是闭包
2 ```javascript function wait(message){
setTimeout( function timer(){
console.log(message);}, 1000);
}
wait("Hello, closure!")
### 为什么要使用闭包?/ 闭包的好处?
- 保护函数的私有变量不受外部干扰。形成不销毁的栈内存
- 把一些函数内的值保存下来。闭包可以实现方法和属性的私有化
### 闭包变量怎么回收呢?
- 如果是全局变量被作为闭包变量的话,则该闭包变量会一直保存到页面关闭。(因为全局上下文会一直存在,不会被回收,除非页面关闭)
- 如果是局部变量被作为闭包变量的话,下面分两种情况讨论
-------------------------- 1 function a(){ var b= 10; return function(){ b++; console.log(num); } } a()(); //11 a()(); //11
在这段代码中,当a函数执行时,返回的匿名函数中存在对a函数中定义的b变量的引用,但随即匿名函数就被执行,使b++。执行结束后,原本存在的对b的引用已经结束,所以函数a的上下文会被回收,b变量也随之回收。当第二次执行就会重新声明变量b,所以两次输出都是11。
---------------------- 2 function a(){ var b = 0; return function(){ b ++; console.log(b); } } var d = a(); d();//1 d();//2
在这段代码中,函数a的执行结果被赋值给了d,d其实就是返回的匿名函数,也就是说d一直存在对函数a的引用。所以即使d被调用,在整个内存中,依然存在一个变量d,指向匿名函数,并存在对函数a中变量的引用,所以执行两次后,b等于2。
### 闭包的一道经典面试题
## js的数据类型
- **一、js的原始类型有哪些? 引用数据类型有哪些?**
- 一共有7种原始值,分别是:
1. string
2. null
3. undefined
4. number
5. boolean
6. symbol
7. bigint
- 引用数据类型:对象Object。包含:
1. 普通对象-Object
2. 数组对象-Array
3. 正则对象-RegExp
4. 日期对象-Date
5. 数学函数-Math
6. 函数对象-Function
(小思考:要是让你聊一聊symbol 和 bigint 这两种原始类型你能聊出来吗?)
### Symbol:
> Symbol是ES6引入的一种原始数据类型,表示独一无二的值,当我们想为一个对象添加新方法,通过创建一个属性名为Symbol类型的方法,可以从根本上防止属性名冲突。
- 如何创建并使用Symbol ?
```javascript
// 通过Symbol()函数创建
let s = Symbol()
typeof s // Symbol
let s1 = Symbol('foo')
let s2 = Symbol({}) //接收对象为参数,会调用该对象的`toString`方法,将其转为字符串
s1 //Symbol(foo)
s2 // Symbol([Object,Object])
let s3 = Symbol()
let s4 = Symbol()
s3 === s2 // false
s1 和 s2 都是Symbol函数的返回值,而且参数相同,但它们是不相等的
前方高能!!!
Symbol属性特性
- Symbol 值不能与其他类型的值进行运算,会报错
- Symbol 值可以显式转为字符串、布尔值 ,但不能转为数值
通过
Symbol函数创建Symbol函数前不能使用new命令。因为生成的 Symbol 是一个原始类型的值,不是对象- 使用
Symbol函数创建Symbol值时,函数的参数只是表示对当前 Symbol 值的描述,这也就能够解释在创建时传入相同参数的Symbol函数的返回值是不相等的。 - 如果 Symbol 的参数是一个对象,就会调用该对象的
toString方法,将其转为字符串,然后才生成一个 Symbol 值。
使用Symbol类型做对象属性名
- 使用Symbol值定义属性时,Symbol值必须放在方括号中,不能用点运算符,因为点运算符后面总是字符串,这会导致读取不到标识名指代的值,而是直接读成一个字符串
- Symbol 作为属性名,遍历对象的时候,该属性不会出现在
for...in、for...of循环中,也不会被Object.keys()、Object.getOwnPropertyNames()、JSON.stringify()返回,也不会被Object.prototype.hasOwnPrototype()访问到。
可读取到对象的Symbol属性的方法
- 有一个
Object.getOwnPropertySymbols()方法,可以获取指定对象的所有 Symbol 属性名。该方法返回一个数组,成员是当前对象的所有用作属性名的 Symbol 值。 Reflect.ownKeys()方法可以返回所有类型的键名,包括常规键名和 Symbol 键名。
- 有一个
Symbol的一些方法
[ES2019] 提供了一个实例属性
description,直接返回 Symbol 的描述Symbol.for()方法可以重新使用同一个 Symbol 值。它接受一个字符串作为参数,然后搜索有没有以该参数作为名称的 Symbol 值。如果有,就返回这个 Symbol 值,否则就新建一个以该字符串为名称的 Symbol 值Symbol.for()和Symbol的区别在于前者会被登记在全局环境中供搜索,后者不会Symbol.for("bar") === Symbol.for("bar")Symbol("bar") === Symbol("bar")// falseSymbol.keyFor()方法返回一个已登记的 Symbol 类型值的key(目前已知Symbol.for()创建的)bigint:
什么是BigInt ?
BigInt是一种新的数据类型,用于当整数值大于Number数据类型支持的范围时。这种数据类型允许我们安全地对
大整数执行算术操作,表示高分辨率的时间戳,使用大整数id,等等,而不需要使用库。为什么需要BigInt? 在JS中,所有的数字都是以双精度64位浮点格式表示的,这会导致JS中的Numbe无法精确表示非常大的整数。(在JS中,Number类型只能安全地表示[-2^53-1 , - 2^53-1]范围的数,任何超出此范围的整数值都可能失去精度,并照成一定的安全性问题)
如何创建并使用BigInt?
创建方法
- 直接再数字结尾追加n
console.log( 9007199254740995n ); // → 9007199254740995n - 用Bigint构造函数
BigInt("9007199254740995"); // → 9007199254740995n
- 直接再数字结尾追加n
基本使用 ``` 10n + 20n; // → 30n 10n - 20n; // → -10n
+10n; // → TypeError: Cannot convert a BigInt value to a number -10n; // → -10n 10n * 20n; // → 200n 20n / 10n; // → 2n 23n % 10n; // → 3n 10n ** 3n; // → 1000n const x = 10n; ++x; // → 11n --x; // → 9n console.log(typeof x); //"bigint"
- 前方高能!!!
1. BigInt不支持一元加号运算符, 这可能是某些程序可能依赖于 + 始终生成 Number 的不变量,或者抛出异常
2. 因为隐式类型转换可能丢失信息,所以不允许在bigint和 Number 之间进行混合操作。当混合使用大整数和浮点数时,结果值可能无法由BigInt或Number精确表示。
3. 不能将BigInt传递给Web api和内置的 JS 函数,这些函数需要一个 Number 类型的数字。尝试这样做会报TypeError错误。
`Math.max(2n, 4n, 6n); // → TypeError`
4. 当 Boolean 类型与 BigInt 类型相遇时,BigInt的处理方式与Number类似,换句话说,只要不是0n,BigInt就被视为truthy的值。
5. BigInt可以正常地进行位运算,如|、&、<<、>>和^
- **二、下面的情况是合法的吗?**—— `console.log('1'.toString())`
是合法的。这个语句运行的过程如下:
```javascript
let s = new Object('1')
s.toString()
s = null
第一步: 创建Object类实例。注意为什么不是String ? 由于Symbol和BigInt的出现,对它们调用new都会报错,目前ES6规范也不建议用new来创建基本类型的包装类。
(小思考:包装类的概念你又知多少?)
第二步: 调用实例方法
toString()。第三步: 执行完方法立即销毁这个实例。
注:整个过程所体现的即是基本包装类型的性质,而基本包装类型也属于基本数据类型,包括Boolean、Number和String
这时候就会引起疑惑,这么搞那和真正的引用类型有什么区别??
基本包装类型 和 引用类型最大的区别在于对象的生存期
基本包装类意味着我们不能在运行时为对象添加属性及方法,因为它们执行完后会立即销毁
let str = '蛙人'
str.age = 23
console.log(str.age) // undefined
- 三、引用类型和原始类型的区别?
原始类型存储的是值,存在栈当中。 对象类型存储的是地址(指针),地址是存在栈中,而值是存储堆当中的。
- 四、函数参数是对象会发生什么?
会造成数据污染,函数传参如果是对象,传的是对象的引用地址,如果函数内对对象进行修改,函数外该对象也会发生改变
测试demo如下:
function test(person){ person.age = 20 person = { name:'袁总', age:30 } return person } const p1 = { name:'胡总', age:25 } const p2 = test(p1) //函数传参传的是对象的引用地址 console.log(p1) //{胡总,20} console.log(p2) //{袁总,30} - 五、0.1+0.2为什么不等于0.3? JS的四则运算需要先将十进制数 -> 二进制数 -> 再通过二进制运算得到运算结果 -> 再转回十进制 先转为二进制,再进行二进制运算,再转为十进制。所以问题就出在一开始转为二进制的过程中,因为Number使用的是IEEE 754 双精度标准 而在十进制 -> 二进制的过程中,0.1和0.2转换成二进制后会无限循环,又由于JS 采用 IEEE 754 双精度版本表示,在标准位数后面多余的位数会被截段,就会出现精度丢失,再通过二进制计算后得到的答案自然不等于0.3。
(不依不饶的面试官:怎么解决这种精度丢失的问题?)
- 原生方法解决 parseFloat((0.1 + 0.2).toFixed(10)) === 0.3 // true
- 使用第三方浮点数运算库 bignumber.js
- 自己解决 原理:拿到两者的最大小数位,将他们转化为整数再来进行四则运算
function arr(nums1 , nums2){
const nums1Digits = nums1.toString().split('.')[1].length
const nums2Digits = nums2.toString().split('.')[1].length
const baseNum = Math.pow(10,Math.max(nums1Digits , nums2Digits))
// 或者用10 ** baseNum
return (num2*baseNum + nums2*baseNum)/baseNum
}
- 通过num.toString().split('.')[1].length 分别拿到两个数的小数位长度
- 两者取最长max
- 两个数分别乘上10 ** max
- 再相加
- 再把max除掉
六、你不知道的Number类型
- Number类型是如何表示的? IEEE 754 双精度版本(64位)将 64 位分为了三段
- 第一位用来表示符号
- 接下去的 11 位用来表示指数
- 其他的位数用来表示有效位,也就是用二进制表示
0.1中的10011(0011)
- Number所能表示的最大范围? [-(2 ** 53 - 1) , (2 ** 53 - 1)] 超出就会失去精度 ```javascript console.log(999999999999999); //=>10000000000000000
9007199254740992 === 9007199254740993; // → true ```
- Number类型是如何表示的? IEEE 754 双精度版本(64位)将 64 位分为了三段
js的类型判断
typeof可以正确判断数据类型? 不能,typeof只能正确判断除null之外的原始类型和Function
typeof null //object ?
因为在 JS 的最初版本中,使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息,000 开头代表是对象,然而 null 表示为全零,所以将它错误的判断为 object 。虽然现在的内部类型判断代码已经改变了,但是对于这个 Bug 却是一直流传下来。
- typeof 和 instanceof 的区别?
- typeof只能正确判断除null之外的原始类型和Function
- instanceof可以准确的判断具备原型的对象
- instanceof能否判断基本数据类型?
能,以这种方式:
class PrimitiveNumber{ static[Symbol.hasInstance](x){ return typeof x === 'number' } } console.log(111 instanceof new PrimitiveNumber()) // trueSymbol.hasInstance用于判断某对象是否为某构造器的实例。因此你可以用它自定义instanceof操作符在某个类上的行为。
实现原理:PrimitiveNumber()是一个类,当对这个类new出来的实例进行instanceof操作时,会自动调用该实例的Symbol.hasInstance方法,这里就是通过自定义这个方法,在方法内通过typeof去进行判断,相当于将原有的instanceof方式重定义,从而可以前言判断基本数据类型
- instanceof进行类型判断的原理是什么?
实例对象的隐式原型 = 构造函数的显式原型
- instanceof实现原理
-> 手写instanceof
function myInstanceof(obj, type) {
let a = obj.__proto__,
b = type.prototype
while (a !== null) { //这里就是第一层没找到,顺着原型链往上找
if (a === b) return true
a = a.__proto__
}
return false
}
- js类型判断的所有方法 —— 从使用上、实现类型判断的原理上、性能上分析区别
五种方法:
typeof、instanceof、Object.prototype.toString.call()、constructor、Array.isArray
- typeof
- 在使用上,typeof可以判断除null以外的原始类型和function
- instanceof
- 在使用上,一般用来判断对象类型,所有的对象类型 instanceof object === true
- 在实现原理上,实质:obj.proto = type.prototype。根据这一实质,对象顺着原型链往上找,直到找到类型的显式原型
- Object.prototype.toString.call()
- 在使用上,Object的原型方法,其他对象通过call/apply调用 -> [Object xxx]
- 可以用于判断所有的数据类型
- constructor
- 实现类型判断的原理是:通过构造函数new出来的对象都有一个constructor属性,指向它的构造函数 如:new Number(1).constructor === Number
- 对undefine和null无效
- 除了对字符串、数组、window、document可以直接进行判断。对其他的数据类型,必须要是被new出来的实例对象才能使用该方法判断类型
- Array.isArray()
- 用于判断对象是不是数组
- 如果没有该方法可以通过方法3来实现
区别和优劣:
- 在使用上的区别
- typeof能够判断除null之外的原始类型和function
- Object.prototype.toString.call()可以用于判断所有的数据类型,常用于判断浏览器内置对象
- instanceof只能用来判断引用类型,不可判断原始类型,且所有的引用类型 instanceof Object 都为true
- constructor对undefined、null无效
- Array.isArray()只能用于判断对象是否为数组
- 在实现原理上的区别
- 当判断数组对象时,Array.isArray优于instanceof,因为前者可以判断来着iframe的数组
- constructor不稳定,主要体现在自定义对象上,如果对象的prototype被重写,原来的constructor引用就会丢失,constructor会默认为Object
- 在性能上,3和5性能一样差,instanceof较好,construcor性能最好(不一定的)
js的类型转换
js中的类型转换只有三种情况
- 转为布尔值
- 转为数字
- 转为字符串
对象转原始值 —— 调用内置的[[ToPrimitive]] eg:{} -> true 怎么转的
- 如果已经是原始类型,那就不需要转换
- 如果不是,就调用x.valueOf(),如果转换为基础类型,就返回转换的值
- 如果2还不能成功转换为基础类型,就调用x.toString(),如果转换为基础类型,就返回转换的值
- 如果都没有转换成原始类型,就会报错
四则运算
- 运算过程中,只要有一方是字符串,所有方都会转换为字符串再进行字符串拼接 例:1 + '1' // '11'
- 只要有一方不是字符串或者数字,那么会将它们先转换为数字或字符串 例:true + true //2
- 除加法运算之外的四则运算,只要其中一方是数字,那么另一方就会被转为数字 ```javascript 4 + [1,2,3]
- [1,2,3].valueOf()
- [1,2,3].toString() //"1,2,3"
- 4 + "1,2,3"
- "41,2,3"
'a' + + 'b'
- 'a' + (+ 'b')
- 'a' + NaN
- 'a' + 'NaN'
- 'aNaN'
## 深浅拷贝问题
### 深浅拷贝的定义
- 浅拷贝:是创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址
- 深拷贝:深拷贝是将一个对象从内存中完整的拷贝一份出来,从堆内存中开辟一个新的区域存放新对象,且修改新对象不会影响原对象。
### JavaScript中实现深浅拷贝的方法
1. Array.prototype.slice()
2. Object.assign(目标对象,源对象)
3. Array.prototype.concat()
4. [...arr]
注意:
Object.assign的一些特点
- 用于对象的合并,将源对象的所有**可枚举的属性**,复制到目标对象
- **Object.assign拷贝的是对象的属性的引用,而不是对象本身**
- 如果目标对象与源对象有同名属性,或多个源对象有同名属性,则后面的属性会覆盖前面的属性
- 如果该参数不是对象,则会先转成对象,然后返回。*由于undefined和null无法转成对象,则会报错* `typeof Object.assign(2) // "object"`
- 拷贝源对象的自身属性(不拷贝继承属性),也不拷贝不可枚举的属性(enumerable: false)Symbol值的属性也会被拷贝
### 实现深拷贝的方法
1. JSON序列化 - `JSON.parse(JSON.stringify())`
2. 手写深拷贝
### 注意: 常见的问题
- 简易的实现深拷贝 (考察手写递归的能力)
- 如何在简易版的基础上解决JSON序列化存在的缺陷?
1. 在拷贝刚开始的时候维护一个WeakMap,记录下已经拷贝过的对象,如果说已经拷贝过,那直接返回它行了。(解决循环引用的问题)
2. 先用`Object.prototype.toString.call(obj)`的方法来识别出各种特殊对象,然后再进行判断,不同的对象进行不同的处理(解决不能拷贝特殊对象的问题)
3. 先利用原型来辨别是箭头函数还是普通函数,如果是普通函数就需要进行一些处理;如果是箭头函数,直接返回本身
- JSON序列化实现深拷贝存在的缺陷?
- 拷贝特殊对象会出错 (衍生问题:**拷贝特殊对象会出现什么问题?**)
1. 拷贝obj中的时间对象 - 时间对象会变成字符串
2. 拷贝obj中的正则对象 / Error对象 - 序列化后会变成空对象
3. 拷贝obj中的函数 / undefined - 序列化后会丢失
4. 拷贝obj中的NaN、Infinity和-Infinity - 序列化的结果会变成null
- 只能序列化对象的可枚举的自有属性
如果obj中的对象是有构造函数生成的, 则使用JSON.parse(JSON.stringify(obj))深拷贝后,会丢弃对象的constructor
- 如果对象中存在循环引用的情况也无法正确实现深拷贝
## this的指向问题
- 默认调用,指向window
- 对象调用,指向该对象
- 做构造函数使用。指向实例对象
- 箭头函数,指向函数所在词法作用域
- call、apply、bind会将this指向传入的第一个参数
## 能不能聊一聊原型和原型链?
对原型链的考察,在前端面试中可以用无处不在来形容,我们也可以在各个博客网站上找到大量关于原型和原型链的文章。但细想一下,当面试官真正丢给你这个问题,你能准确的描述出聊清楚原型和原型链吗?
回答的步骤如下:
- **什么是原型对象:** 每一个JavaScript对象(null除外)在创建的时候就会与之关联另一个对象,这个对象就是我们所说的原型对象,每一个对象都会从原型"继承"属性。
- **函数的原型和对象的原型:**
- 每个函数都有一个prototype属性,该属性指向函数的原型
- 每个对象都有一个__proto__属性,该属性指向对象的原型
- **什么是原型链:** 当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止。这条查找的路径就叫原型链
- **如何顺着原型链查找?** —— 这张图再经典不过了
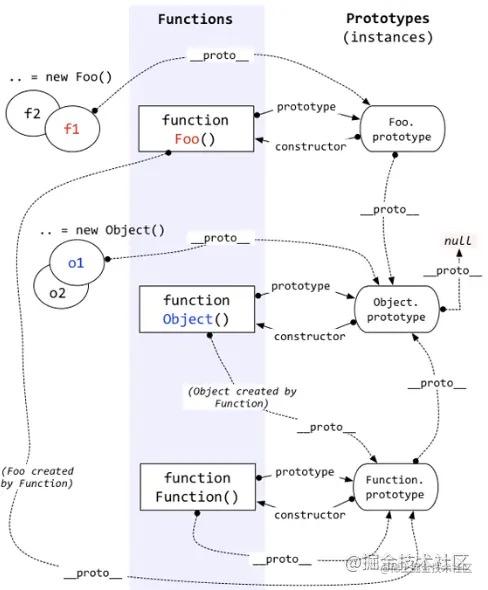
## JS中的垃圾回收机制
### 为什么要研究垃圾回收机制?
便于在极端的环境下能够分析出系统性能的瓶颈。
便于深入理解JS的闭包特性、以及内存的高效使用
### 为什么要限制内存? 这个限制是可以调整的
从回收的角度来看,因为**JS是一个单线程运行**的,如果不做内存限制,一旦进入**垃圾回收**,其他所有的东西都要暂停,而你的垃圾又是巨大的,非常耗时的。这会导致JS代码执行会一直没有响应,造成应用卡顿,导致性能下降。
```javascript
// 这是调整新生代这部分的内存,单位是 KB。
node --max-new-space-size=2048 xxx.js
// 这是调整老生代这部分的内存,单位是MB。后面会详细介绍新生代和老生代内存
node --max-old-space-size=2048 xxx.js
全停顿
其实就是在进行垃圾回收的时候,JS的应用逻辑会进入全停顿状态
栈内存的回收
当ESP指针下移,也就是上下文切换之后,栈顶的空间就自动被回收。
堆内存(= 新生代 + 老生代)的回收
新生代内存的回收(即是临时分配的内存,存活时间短。)
新生代内存回收的算法:Scavenge算法。主要是解决内存碎片的问题 特点:内存只能使用新生代内存的一半,时间性能非常优秀
Sacavenge算法回收过程:
- 将新生代内存空间一分为二:From表示正在使用的内存,To是目前闲置的内存
- 垃圾回收时,v8先将From部分的对象检查一遍,如果是存活对象就复制到To内存中(在To内存中按照顺序从头放置:这样做的好处在于,不会导致稍微大一点的对象没办法进行空间分配),如果是非存活对象直接回收
- 完成后,二者角色对调,现在From处于闲置状态,To正在使用,如此循环
老生代内存的回收(常驻内存,存活时间长) 增量标记 -> 增量清除 -> 增量标记 -> 延迟清理
紧接着上面,如果新生代变量经过多次回收后依然存在,那就会被放入老生代内存中,这种现象叫做晋升
触发晋升的情况:
- 已经经历过一次Scavenge回收
- To(闲置)空间的内存占用超过25%
下面正式进入到老生代内存:
- 进行标记-清除。先遍历堆中全部的变量,全部做上标记;再给
正在使用的变量和被强引用的变量取消标记;最后对有标记的变量进行空间回收(这里就会触发和新生代一样的问题:存活对象的空间不连续对后续的空间分配造成障碍) - 整理内存碎片(Mark-Compact)。将存活的对象移动到一边,然后再清理端边界外的内存。(这是整个过程中最耗时间的部分)
注意:
因为Mark-Compact需要移动对象,所以执行速度上,比Mark-Sweep要慢。所以,V8主要使用Mark-Sweep算法,然后在当空间内存分配不足时,采用Mark-Compact算法
为了防止因为老生代垃圾回收任务重,导致的性能影响。老生代采用增量标记 - lazy sweeping(延迟清理)的方案:
增量标记:每次只标记一小部分的内存空间,每执行部分就让应用逻辑执行一会,循环直至完成标记
延迟清理:
- 发生在增量标记之后
- 堆此时准却的知道有多少空间能被释放
- 延迟清理是被允许的,因此页面的清理可以根据需要进行清理
- 当延迟清理完成后,增量标记将重新开始
问题
- 新生代的这种回收算法的特点是什么? 有什么好处?
避免因对存活对象的空间不连续堆后续的空间分配造成障碍
- 老生代为什么不采用同样的方法? 老生代中的对象有两个特点,第一是存活对象多,第二个存活时间长。若在老生代中使用 Scavenge 算法进行垃圾回收,将会导致复制存活对象的效率不高,且还会浪费一半的空间。
结语
至此,我们对vue基础的回顾就到这了,**前端职场人技术提升